Your Agent's Memory
Shouldn't Be a
Markdown File
Give it a database brain instead — with chDB.
Auxten Wang · Technical Director @ ClickHouse · Creator of chDB

Auxten Wang
@auxten · auxten.com
How agents "remember" today
Append lines to a text file — memory.md, CLAUDE.md, AGENTS.md — then paste the whole thing back into the prompt.
It works on day one. It does not survive contact with a real session.
A familiar agent failure
Yesterday
It hit a constraint and found the fix that worked.
Today
Same task. It reads the prompt — not yesterday's fix.
Result
Repeats the failed plan. Burns tool calls on retries.
A markdown file is write-only memory
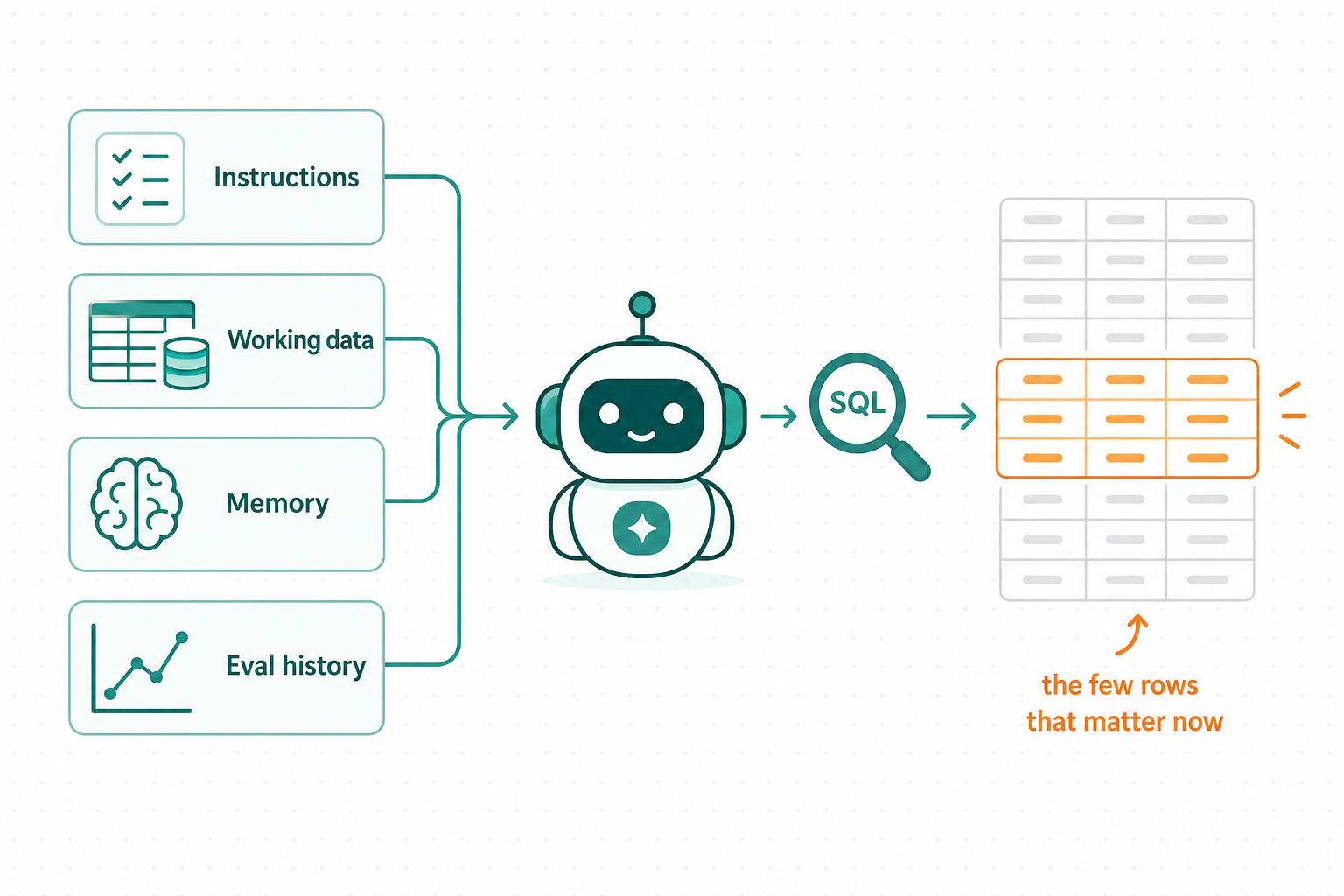
Your agent's context is really data
Four kinds of it — and recall is choosing the few that matter now.
"Can't I just use what I have?"
SQLite
Great for tiny state. No columnar scan, no vectors, no remote files.
Pandas
Great in memory. Dies past RAM. Can't query files you never loaded.
DuckDB
Closest match — but fewer formats and no mature cloud path.
Vector DB
Similarity only. Can't filter + join + aggregate + audit in one query.
chDB: a rocket engine
on a bicycle
The ClickHouse engine, embedded in your Python process — SQLite-simple, built to scan millions of rows.
# pip install chdb
from chdb import session as chs
sess = chs.Session("./agent")
sess.query("SELECT count() FROM file('log.pq')")
It drops into your Python data stack
70+ formats
Parquet, CSV, JSON, Arrow, ORC — read & write, no converters.
Zero-copy Pandas / Arrow
Query a DataFrame or Arrow table in place — no copy, no load.
Pandas-style API
Prefer DataFrames to raw SQL? chDB v4 speaks that too.
What good agent memory needs
Memory the agent can filter, rank, and grow — not a prompt blob.
Memories are rows
Filter, rank, and audit them with plain SQL.
Recall = similarity + filter
Meaning and business rules in one query.
Local now, cloud later
Same SQL from laptop to ClickHouse Cloud.
Recall is one SQL query
Rank by meaning, keep the active ones, pinned first.
cosineDistance
how close two meanings are (0 = identical)
Need project / tags / task history? Add a WHERE or JOIN — same query.
SELECT content,
1 - cosineDistance(embedding, :q) AS meaning
FROM memory
WHERE is_deleted = 0 -- rules
ORDER BY pinned DESC, meaning DESC
LIMIT 8Memory has a lifecycle
Beliefs change. "Use Poetry" → "this repo standardizes on uv."
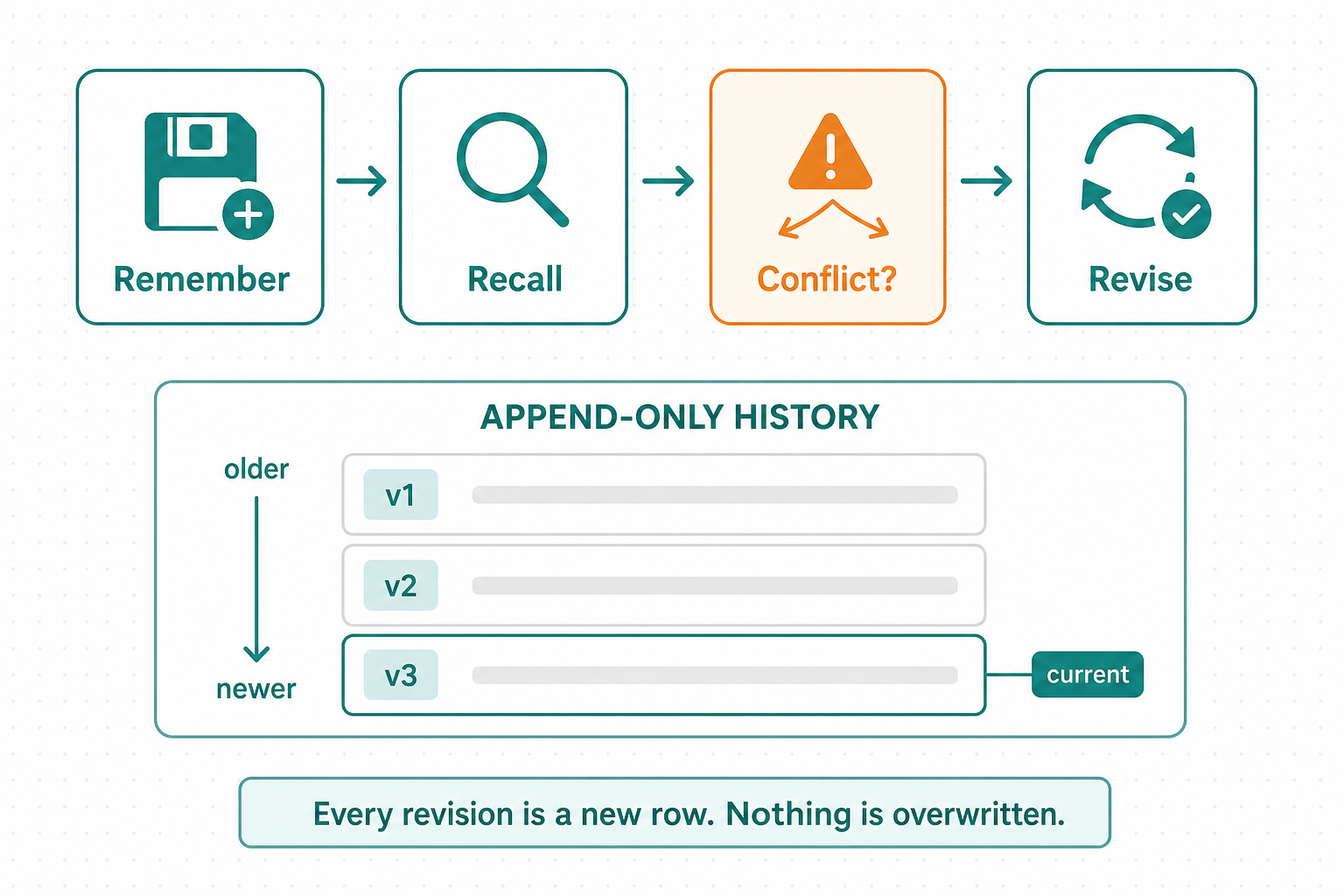
Don't update it.
Append to it.
Every revision is a new immutable row with a version. Deletes are a soft flag, never a real delete.
(For history, skip ReplacingMergeTree — it converges to one state and folds the past away.)
CREATE TABLE memory
(
memory_id UUID,
content String,
embedding Array(Float32),
version UInt64,
is_deleted UInt8 DEFAULT 0,
created_at DateTime64(3) DEFAULT now64()
)
ENGINE = MergeTree
ORDER BY (memory_id, version);One append-only table answers all three
-- NOW: latest version per memory, minus soft-deletes
SELECT * FROM (
SELECT * FROM memory ORDER BY memory_id, version DESC LIMIT 1 BY memory_id
) WHERE is_deleted = 0;
-- HISTORY: how this belief evolved
SELECT * FROM memory WHERE memory_id = :id ORDER BY version;
-- POINT-IN-TIME: what did the agent believe as of version t?
SELECT * FROM (
SELECT * FROM memory WHERE version <= :t
ORDER BY memory_id, version DESC LIMIT 1 BY memory_id
) WHERE is_deleted = 0;So… should it be a markdown file?
Memory ≈ Observability ≈ History
All three are append-only by nature — the same shape as the memory model. One local engine serves them as a single query surface.
Agent memory
decisions, facts, prior solutions.
Observability
traces of what the agent did.
History
the full conversation log.
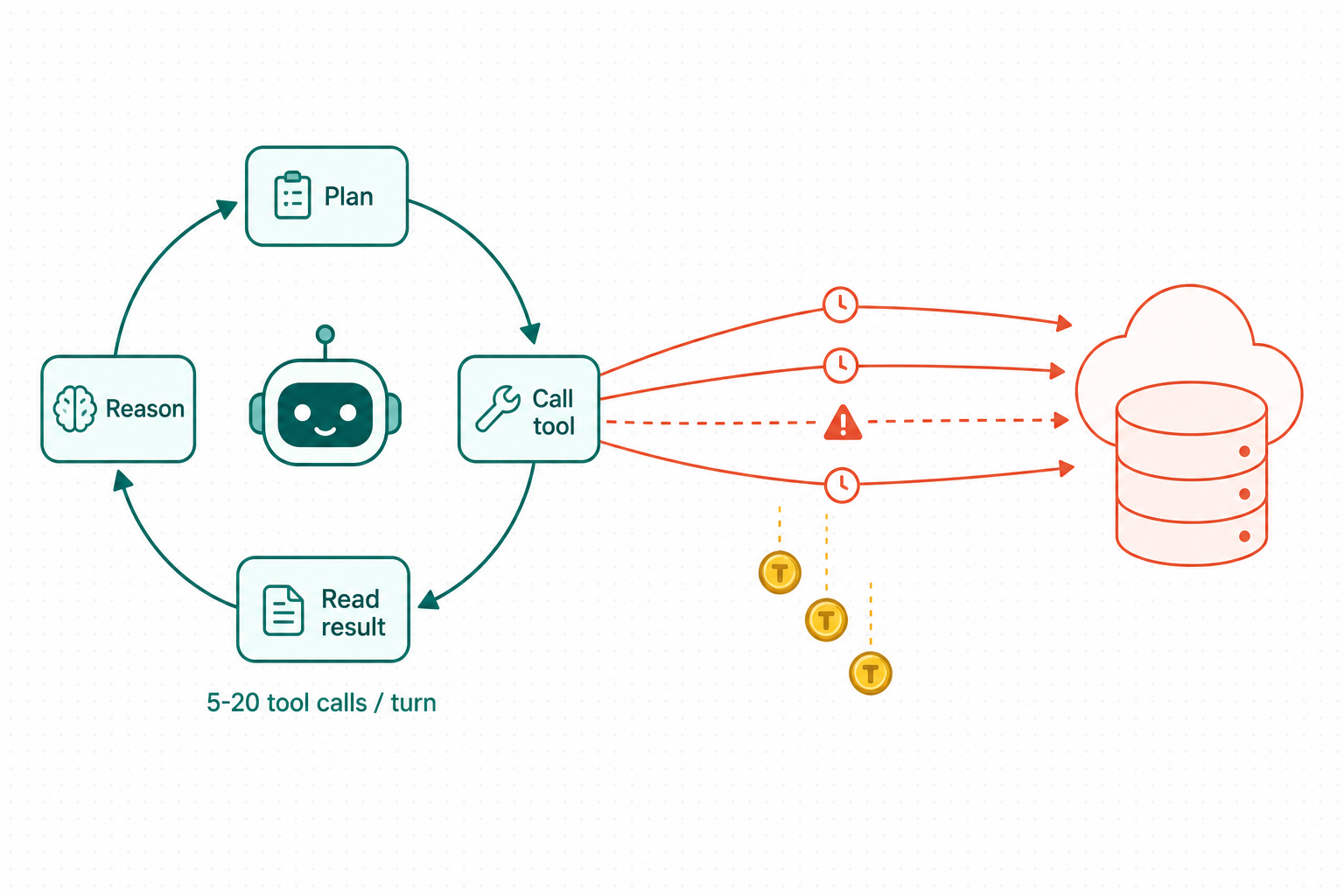
Recall sits inside the agent loop
5–20 tool calls / turn. Put recall over the wire and jitter becomes think-time jitter — and tokens.
Start local, graduate to ClickHouse
chDB session on a laptop or agent runtime
ClickHouse Cloud when memory is shared or large
# Day 1 — query local memory
sess.query("SELECT content FROM memory WHERE project = 'checkout'")
# Day 100 — repoint the same name at the cluster (SELECT unchanged)
sess.query("""CREATE OR REPLACE VIEW memory AS
SELECT * FROM remote('cloud:9440', db, memory)""")
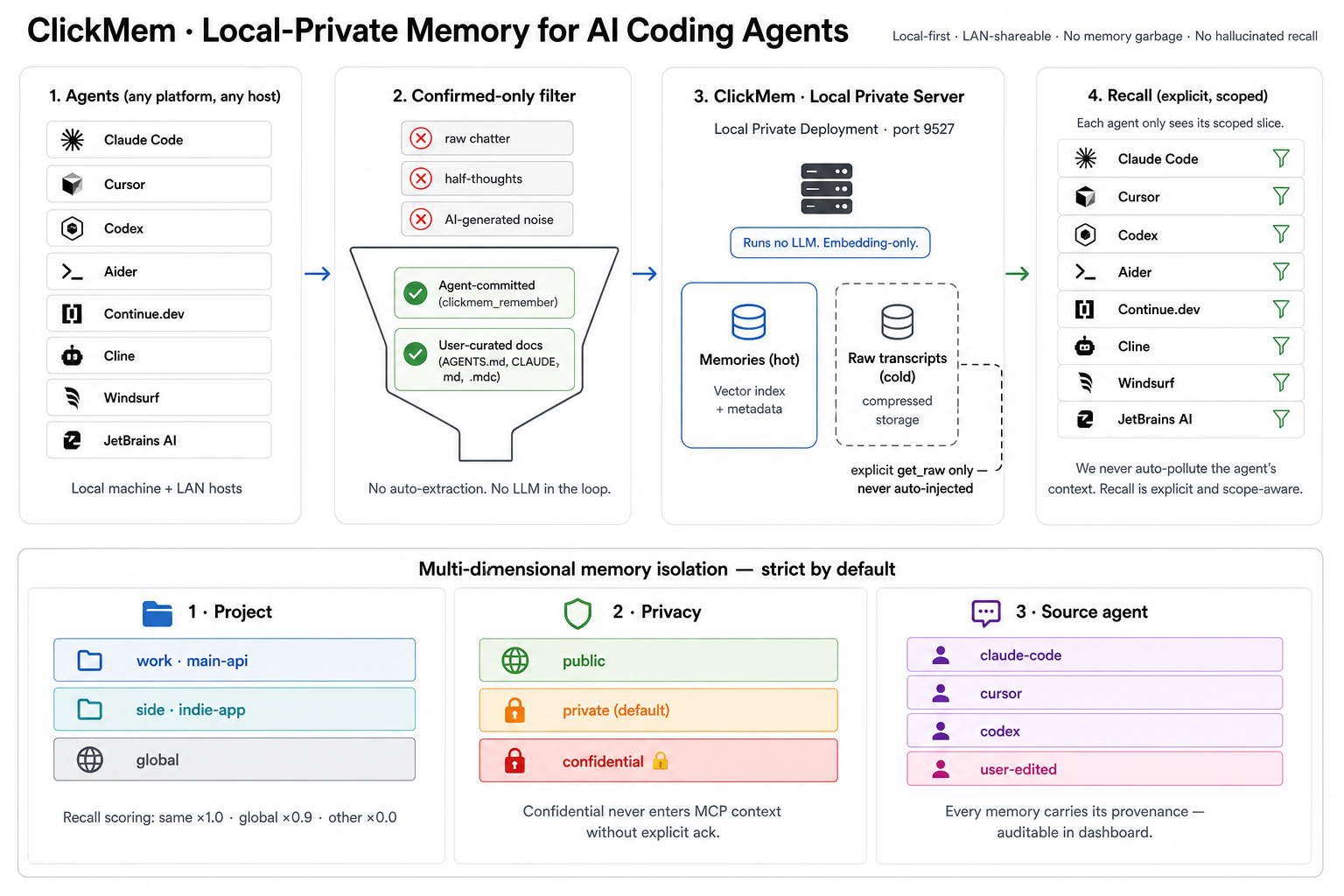
Meet ClickMem
The whole pattern — lifecycle, recall, local-first — packaged open-source on chDB.
Embeddings: Qwen/Qwen3-Embedding-0.6B — runs locally, nothing leaves the box.
github.com/auxten/clickmem
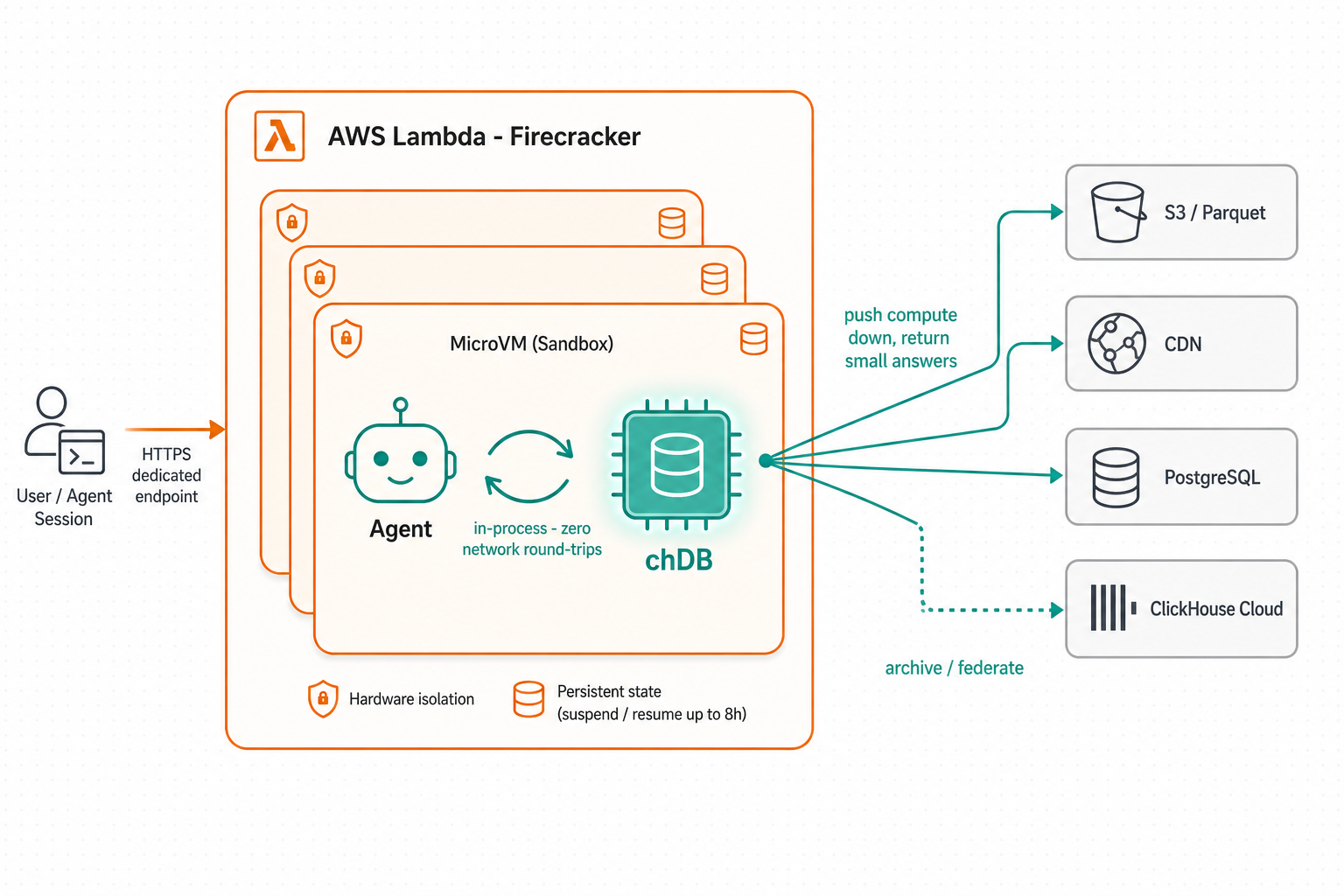
Where the brain runs: AWS Lambda MicroVMs
chDB is the only data-infrastructure launch partner for Lambda MicroVMs. Every isolated session carries its own private chDB — Firecracker isolation, suspend / resume, zero network round-trips.
Three takeaways
Context is data.
Filter it, rank it, join it, version it, evaluate it.
Recall is a query.
Semantic meaning + business rules, in one SQL.
Don't store memory in a markdown file.
chDB now; ClickHouse when it's shared or large.
Give your agent a database brain
pip install chdbBuild it
github.com/chdb-io/chdb
github.com/auxten/clickmem
Read it
Docs: clickhouse.com/docs/chdb
Blog & slides: auxten.com
chDB is what your agent thinks with.
Lambda MicroVMs is where it thinks, in private.