Giving Your AI Agent a Database Brain
A local SQL database your agent can actually query — with chDB.
Auxten Wang · Technical Director @ ClickHouse · Creator of chDB

Auxten Wang
@auxten · auxten.com
A familiar agent failure
Yesterday
It hit a constraint and found the fix that worked.
Today
Same task. It reads the prompt — not yesterday's fix.
Result
Repeats the failed plan. Burns tool calls on retries.
Your agent's context is really a pile of data
Context engineering just means choosing what the agent sees. Four kinds of data:
Instructions
Rules, constraints, preferences.
Working data
Files, tables, API results, logs.
Memory
Decisions, facts, prior solutions.
Eval history
What worked, what failed, what changed.
"Can't I just use what I already have?"
SQLite
Great for tiny state. No columnar scan, no vectors, no remote files.
Pandas
Great in memory. Dies past RAM. Can't query files you never loaded.
DuckDB
Closest match — but fewer formats and no mature cloud.
Vector DB
Similarity only. Can't filter + join + aggregate + audit in one query.
ClickHouse in 60 seconds
Analytical database
Open-source. Fast SQL over huge tables: logs, events, metrics.
Columnar engine
Stores by column, so scans over millions of rows stay fast.
More than storage
A real engine: SQL, JSON, arrays, text search, vector distance.
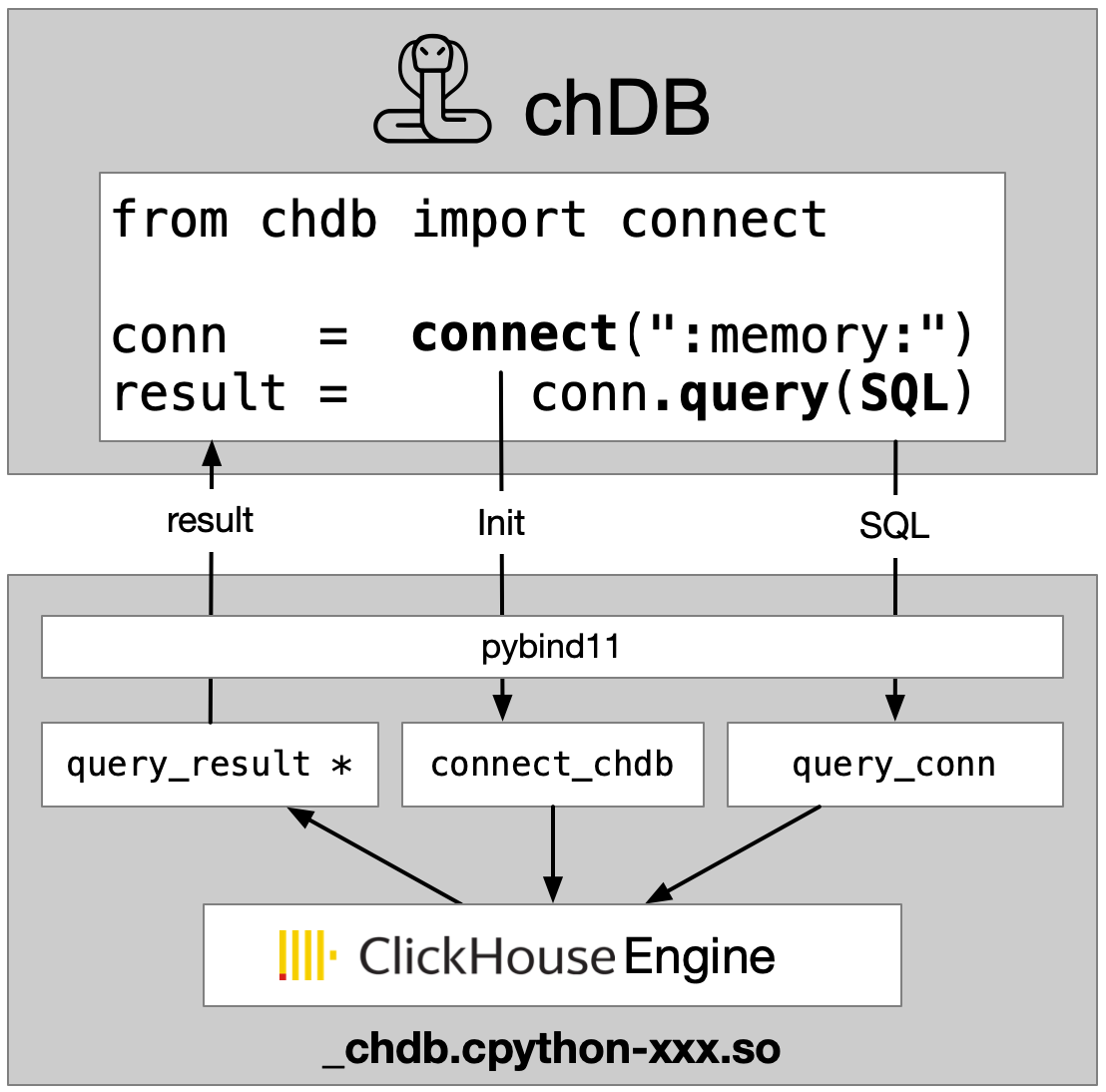
chDB: a rocket engine on a bicycle
The ClickHouse engine, embedded in your Python process — SQLite-simple, 100× faster for analytics.
# pip install chdb
from chdb import session as chs
sess = chs.Session("./agent")
sess.query("SELECT count() FROM file('log.pq')")your agent code
chDB · ClickHouse engine
runs in the same process
files · DataFrames · local tables

chDB drops into your Python data stack
70+ data formats
Parquet, CSV, JSON, Arrow, ORC — read and write, no converters.
Zero-copy Pandas & Arrow
Query a DataFrame or Arrow table in place — no copy, no load.
Pandas-style API
Prefer DataFrames to raw SQL? chDB speaks that too.
Your Pandas Code
One Line Change
Under the Hood
Inside the Engine
SELECT city,
AVG(salary) AS mean,
SUM(salary) AS sum,
COUNT(salary) AS count
FROM file('employee_data.csv',
'CSVWithNames')
WHERE age > 25
AND salary > 50000
GROUP BY city
ORDER BY mean DESC
LIMIT 10
Join anything with SQL
Three sources, one query — no load step.
What good agent memory needs
Memory the agent can filter, rank, and grow — not a prompt blob.
Memories are rows
Filter, rank, and audit them with plain SQL.
Recall = Similarity + Filter
Meaning and rules in one query.
Local now, cloud later
Same SQL from laptop to ClickHouse.
Agent memory has a lifecycle
remember
explicit decision
recall
similarity + filter
conflict?
similar but different
revise
better belief wins
Old memory
"Use Poetry for this repo."
Revised memory
"This repo now standardizes on uv." (old row → conflicted)
Recall is one SQL query
Rank memories by meaning, keep the active ones, pinned first.
cosineDistance
how close two meanings are, as a number (0 = identical)
Need project, tags, or task-history? Add WHERE / JOIN lines — same query.
SELECT
content,
1 - cosineDistance(embedding, query_vec) AS meaning
FROM memories
WHERE status = 'active'
ORDER BY pinned DESC, meaning DESC
LIMIT 8import chdb.datastore as pd
m = pd.DataStore(
table="memories", database="./agent_context")
m = m.assign(
meaning=1 - pd.F.cosineDistance(
m.embedding, pd.F.array(*query_vec)))
m[m.status == "active"].sort_values(
["pinned", "meaning"], ascending=False).head(8)Recall sits inside the agent loop
In the loop
Recall runs many times per turn — jitter becomes think-time jitter.
Retries hurt twice
A timed-out call is retried — each retry re-sends the whole prompt.
Local wins
In-process recall is orders of magnitude faster. No tail, no retries.
Start local, scale to ClickHouse
chDB session on a laptop or agent runtime
ClickHouse Server or Cloud when memory is shared or large
# Day 1 — query local memory
sess.query("SELECT content FROM memories WHERE project = 'checkout'")
# Day 100 — repoint the same name at the cluster (SELECT unchanged)
sess.query("""CREATE OR REPLACE VIEW memories AS
SELECT * FROM remote('cloud:9440', db, memories)""")Honest note: remote reads pay the network cost again — keep the hot path local.
Meet ClickMem
That whole pattern — lifecycle, recall, local-first — packaged as an open-source project on chDB. Build the core yourself:
create
memories table
insert
explicit decisions
recall
similarity + filter
evaluate
which memory helped?
sess = chs.Session("./agent_context")
sess.query("CREATE TABLE memories (...) ENGINE = MergeTree ORDER BY id")
sess.query("INSERT INTO memories VALUES (...)")
sess.query("""
SELECT content FROM memories
WHERE created_at > now() - INTERVAL 30 DAY -- filter
ORDER BY cosineDistance(embedding, ?) LIMIT 8 -- similarity
""")Embeddings: Qwen/Qwen3-Embedding-0.6B via sentence-transformers, runs locally.
Three takeaways
Context is data.
Filter it, rank it, join it, evaluate it.
Recall is a query.
Semantic meaning + simple rules, in one SQL.
Local first.
chDB now; ClickHouse when shared or large.
github.com/chdb-io/chdb · github.com/auxten/clickmem